I shortly introduced via a simple weather
prediction model the use of Markov chains and respectively Python
implementation. Here we will have a look at a stock index – I take the S&P
500 index for the period Aug 5, 2014 to Aug 5, 2015 (252 daily returns) as an
example.
First we calculate daily returns and decide on three
states of the daily changes – decrease (coded
as ‘1’), neutral (coded as ‘2’)
and increase (coded as ‘3’). Then we
calculate 9 states (resp. probabilities based on historical figures):
(i)
yesterday
index decreased and today is down as
well (coded as ‘11’)
(ii)
yesterday
index decreased but today is neutral (coded
as ‘12’)
(iii)
yesterday
index decreased but today is up (coded as
‘13’)
(iv)
yesterday
index was neutral but today is down (coded
as ‘21’)
(v)
yesterday
index was neutral and today is neutral too (coded
as ‘22’)
(vi)
yesterday
index was neutral but today is up (coded
as ‘23’)
(vii)
yesterday
index increased but today is down (coded
as ‘31’)
(viii)
yesterday
index increased but today is neutral (coded
as ‘32’)
(ix)
yesterday
index increased and today is up as well (coded
as ‘33’)
The algorithm I follow is as follows: (1) count
all daily decreases, neutral and increases in index values (i.e. index returns
over 1-day period), then (2) count all cases within the nine states (as stated
above) – from prior day decrease to current day decrease, from prior day
decrease to current day increase and so on and finally (3) calculating the
probabilities is straightforward: divide state coded as ‘11’ by total number of
daily decreases, divide state coded as ‘12’ by total number of daily decreases,
divide state coded as ‘21’ by total number of daily increases and divide state
coded as ‘22’ by total number of daily increases and so on.
For instance:
Counts
|
||
Daily
decreases (state '1')
|
121
|
|
Daily neutral
(state '2')
|
6
|
|
Daily increases
(state ‘3’)
|
125
|
|
Counts
|
Probabilities
|
|
State ‘11’
|
57
|
0.47
|
State ‘12’
|
1
|
0.01
|
State ‘13’
|
63
|
0.52
|
State '21'
|
3
|
0.5
|
State '22'
|
0
|
0
|
State '23'
|
3
|
0.5
|
State '31'
|
61
|
0.49
|
State '31'
|
4
|
0.04
|
State '33'
|
59
|
0.47
|
To
From
|
Decrease
(‘1’)
|
Neutral
(‘2’)
|
Increase
(‘3’)
|
Decrease
(‘1’)
|
0.47
(‘11’)
|
0.01
(‘12’)
|
0.52
(‘13’)
|
Neutral
(‘2’)
|
0.5
(‘21’)
|
0
(‘22’)
|
0.5
(‘23’)
|
Increase
(‘3’)
|
0.49
(‘31’)
|
0.04
(‘32’)
|
0.47
(‘33’)
|
For S&P 500 example there is 47%
probability of decrease today given yesterday index decreased and 47%
probability of increase today given increased yesterday. Quite fair!
Solving for the steady state probabilities (as
explained here: http://elenamarinova.blogspot.com/2015/06/markov-chains-in-python-simple-weather.html) 49% of the days the index will increase and 48% of the days the index will
experience a decrease over the prior day. The steady state is already
independent on the current state, this is the memoryless property of the
process.
(1) transition=np.array([[0.47, 0.01, 0.52],[0.5, 0.00, 0.5], [0.49, 0.04,0.47]])
initial=np.array([0,0,1]) #today is increase
Result: [decrease, neutral, increase]
[ 0.49 0.04 0.47]
(1) transition=np.array([[0.47, 0.01, 0.52],[0.5, 0.00, 0.5], [0.49, 0.04,0.47]])
initial=np.array([0,0,1]) #today is increase
Result: [decrease, neutral, increase]
[ 0.49 0.04 0.47]
[ 0.4806 0.0237 0.4957] [ 0.480625 0.024634 0.494741] [ 0.48063384 0.02459589 0.49477027] [ 0.48063328 0.02459715 0.49476957] [ 0.48063331 0.02459712 0.49476958]
(2) transition=np.array([[0.47, 0.01, 0.52],[0.5, 0.00, 0.5], [0.49, 0.04,0.47]])initial=np.array([1,0,0]) #today is decreaseResult: [decrease, neutral, increase][ 0.47 0.01 0.52] [ 0.4807 0.0255 0.4938] [ 0.480641 0.024559 0.4948 ] [ 0.48063277 0.02459841 0.49476882] [ 0.48063333 0.02459708 0.49476959] [ 0.4806333 0.02459712 0.49476958](3) transition=np.array([[0.47, 0.01, 0.52],[0.5, 0.00, 0.5], [0.49, 0.04,0.47]])initial=np.array([0,1,0]) #today is neutralResult: [decrease, neutral, increase]
[ 0.5 0. 0.5] [ 0.48 0.025 0.495] [ 0.48065 0.0246 0.49475] [ 0.480633 0.0245965 0.4947705] [ 0.48063331 0.02459715 0.49476954] [ 0.48063331 0.02459711 0.49476958]
A somehow more decisive stock market example we found in Wikipedia (https://en.wikipedia.org/wiki/Markov_chain):Labelling the state space {1 = bull, 2 = bear, 3 = stagnant} the transition matrix for this example is
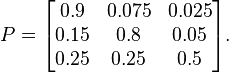
Assuming we are at initial state 'bear' for the probabilities the result is:
Result: [bull, bear, stagant]










